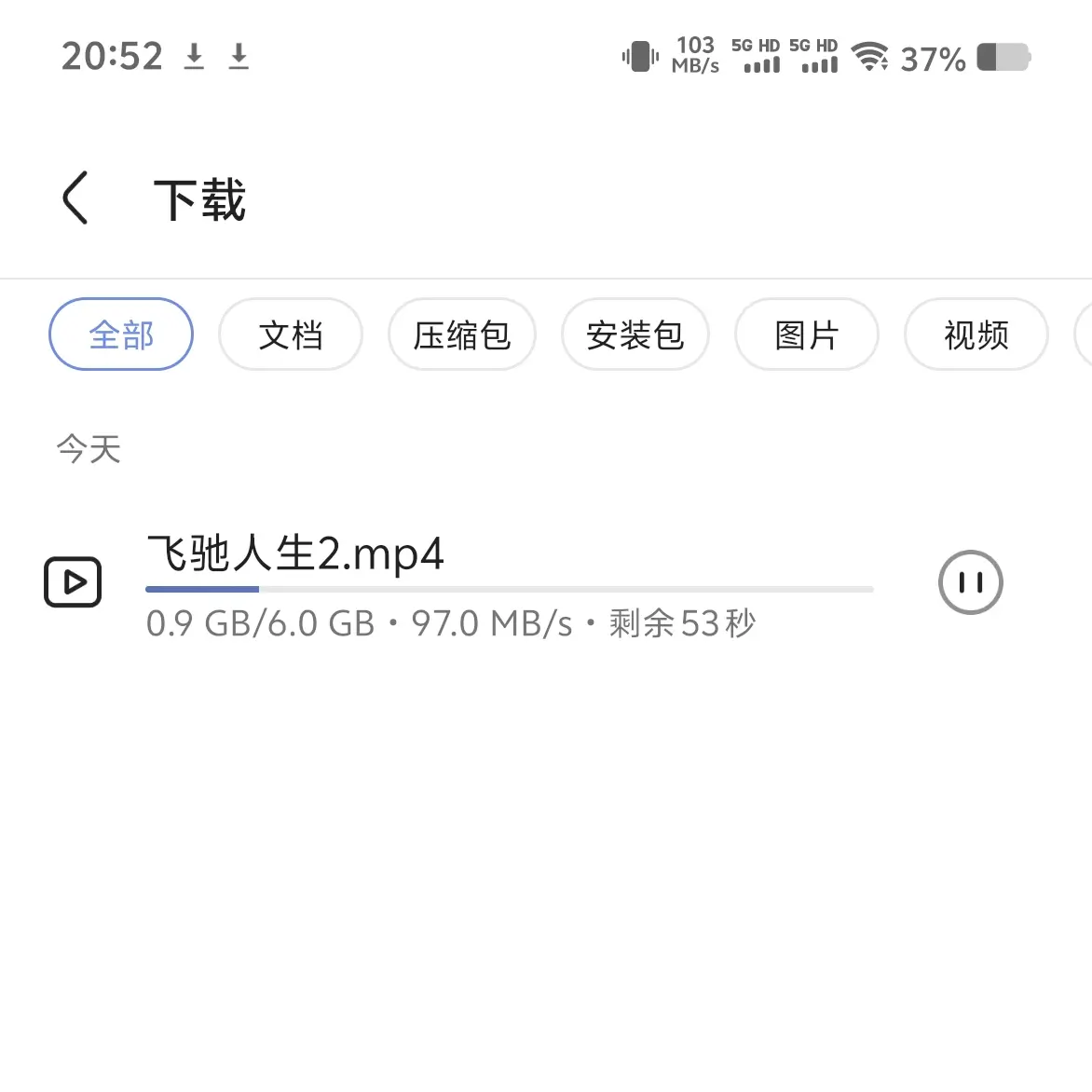
Midscene.js 一共就三大 API:Action、Query、Assert
Action 交互
描述步骤并执行交互。例如,在 GitHub 上交互:查找 GitHub 上的 Twikoo 项目,点进详情页,点个 Star——
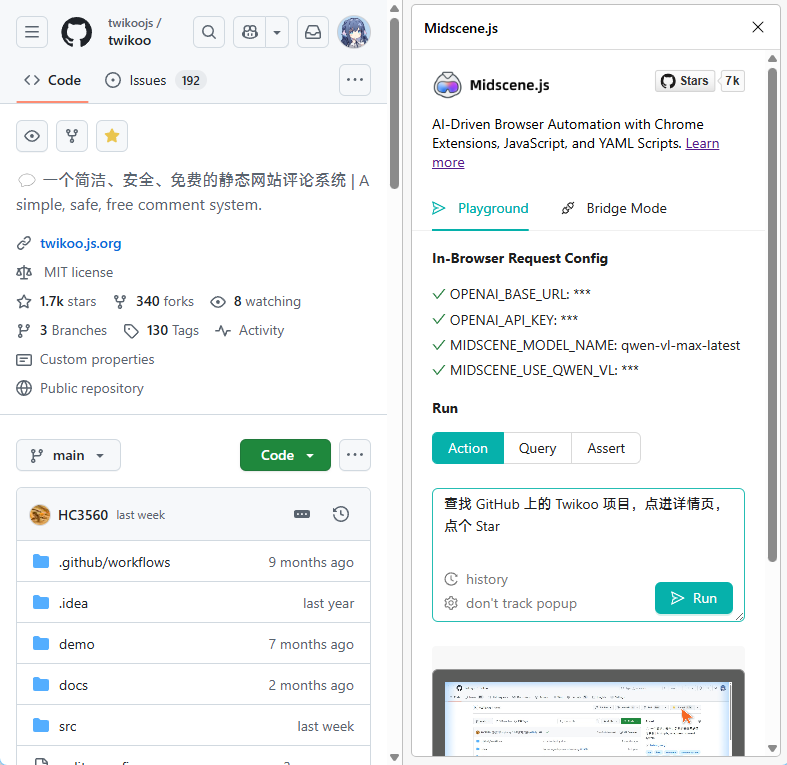
Query 提取
从 UI 中“理解”并提取数据,返回值是 JSON 格式,想要什么数据结构,它都可以给你。例如,在面试题宝典网站上提取:string[],所有面试题目——
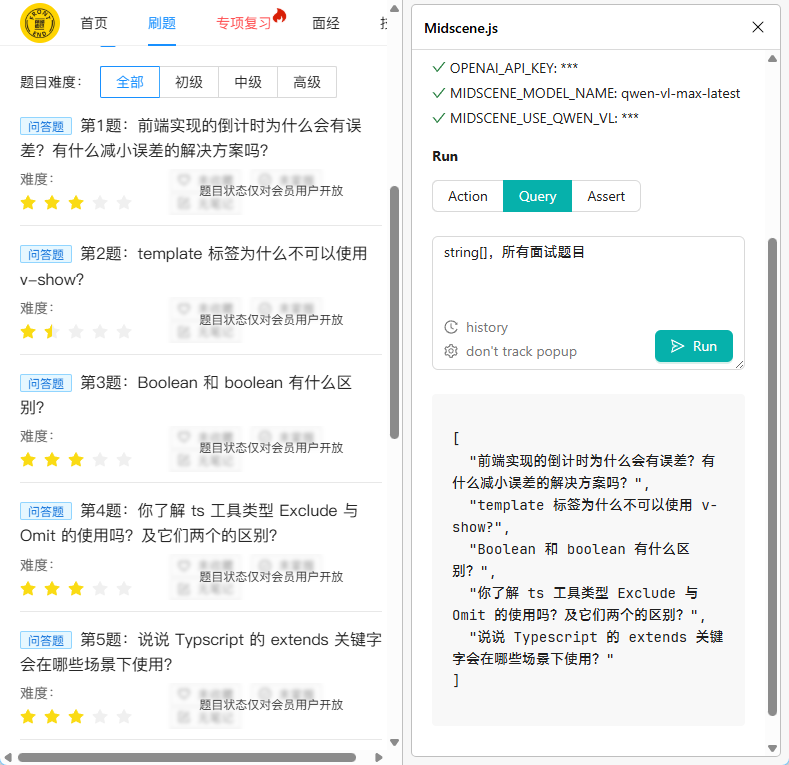
Assert 断言
判断是否符合指定条件。例如,在智能家庭页面断言:电脑是关着的——
大模型支持情况
项目最初仅支持 GPT-4o 模型,跑一行用例的成本在 ¥0.1 左右,还挺贵的,后来支持了 Qwen-2.5-VL 和 UI-TARS,成本就大幅降低了。以下就以千问模型为例,带领大家上手这个神奇的插件。
安装
可以直接从 Chrome 商店安装:
https://chromewebstore.google.com/detail/midscene/gbldofcpkknbggpkmbdaefngejllnief
配置
从浏览器右上角的插件菜单中打开 Midscene.js 的侧边栏,会提示 No config,点击按钮会弹出 Env Config 的设置框,在里面配置以下变量
1 | OPENAI_BASE_URL="https://dashscope.aliyuncs.com/compatible-mode/v1" |
其中的 OPENAI_API_KEY 需要你自己申请,申请的地址是:
https://bailian.console.aliyun.com/?apiKey=1#/api-key
以上链接不包含推广,如果你是首次开通阿里云百炼,新用户是有免费额度的,请注意额度的有效期,避免浪费~
测试
接下来用自然语言随便写一条指令,点击 Run 按钮,见证 AI 开始接管你的浏览器……
代码集成
接下来我们尝试编写爬虫,组合这三大 API,完成复杂的自动化任务。
建一个新的 Node.js 项目,安装所需的依赖——
1 | pnpm install @midscene/web tsx --save-dev |
编写脚本 main.ts,执行你想要进行的操作,例如,打开必应,输入 iMaeGoo 点击搜索,并输出搜索结果——
1 | import { AgentOverChromeBridge } from "@midscene/web/bridge-mode"; |
启动你的 Chrome 插件,点击 Bridge Mode,再点击 ‘Allow connection’ 按钮——
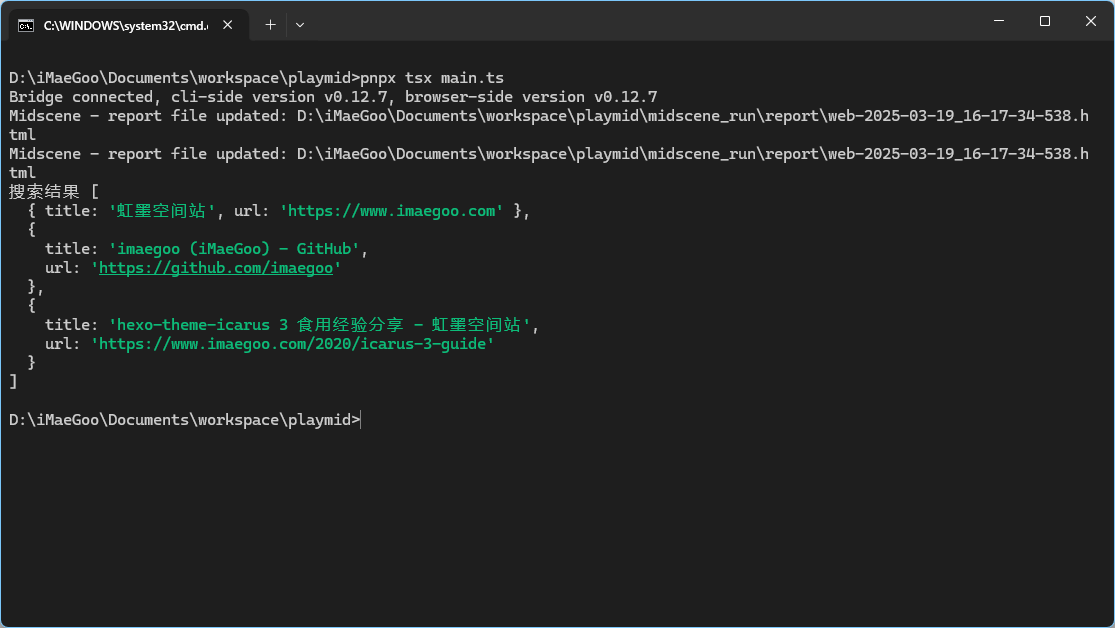
随后运行脚本——
1 | pnpx tsx main.ts |
可以看到脚本成功打开必应搜索 iMaeGoo 并打印出了搜索结果——